Vamos a utilizar los datos de nuestro histórico de la cuenta de Spotify. Se tienen que solicitar a través de la sección de privacidad de nuestra cuenta (a través de este enlace se puede).
La intención es emular el Spotify Wrapped original, además de poder constatar si los datos mostrados por el Wrapped coinciden con los obtenidos por nuestra cuenta.
Si se manipulan los datos del archivo .json para meterlo todo en un archivo, este código puede servirle a cualquier persona que quiera hacer lo mismo!
Creando el dataframe para el análisis
Una vez solicitado el historial de reproducción ampliado, tras pasar unos días recibiremos en nuestro correo una carpeta con varios archivos, con formato .json.
Para poder cargar de manera más sencilla los datos dentro de RStudio, he seleccionado previamente los archivos con información de 2024 y los he fusionado (en el bloc de notas, con un simple copia-pega) para tener sólo 1 archivo .json.
Importante: Respetar el formato de los archivos .json es necesario para que la carga de los datos no contenga errores, sobretodo hay que ir con cuidado de no equivocarse con un símbolo tipo “{”; “}”; “[”; ”]” o similares.
Un problema adicional que tiene el archivo del histórico es que viene en formato nested, es decir, que cada reproducción está representada por un bloque de texto, no una fila o una columna, por lo que no puede ser interpretado directamente como un dataframe por el programa. Por eso, utilizaremos el paquete jsonlite para extraer los datos de nuestro archivo .json y convertirlo en un dataframe sobre el cual poder trabajar. En esta parte del código también añadimos los paquetes con los que vayamos a trabajar a lo largo del código.
El dataset contiene observaciones sobre un conjunto de 19996 reproducciones de canciones. Hay 19 variables, pero no todas son necesarias o útiles para el análisis que queremos realizar, por lo que podemos eliminar algunas y editar otras.
Llama especialmente la atención que el dataframe tiene las fechas/timestamps en formato character, no en formato date. Para ello, utilizaremos el paquete lubridate para crear una nueva variable en formato date que nos será útil más adelante. Adicionalmente, nos desharemos de las variables que no nos interesan para el análisis:
El código indica que hemos escuchado un total de 2181 artistas diferentes. No es el mismo dato, pero se acerca lo suficiente como para considerar que no se trata de un error en el cálculo de Spotify, si no que existe una diferencia en el marco temporal elegido, ya que yo he recibido datos posteriores a la fecha de la publicación del Wrapped.
“Reverse Engineering” el intervalo temporal
Con el siguiente trozo de código representaré la evolución del número de artistas diferentes escuchados a lo largo del año, intentando encontrar el día exacto en el que ese número llega a los 2070 que indica Spotify, para así estar seguro de que los datos empleados son los mismos que los de Spotify.
Este fragmento de código ha sido especialmente complejo hasta encontrar el uso correcto para distinct del paquete dplyr, que elimina los duplicados globales del dataset. Por ejemplo, independientemente del numero de veces que haya escuchado, por ejemplo, a Daft Punk, distinct no tiene en cuenta ninguno excepto el primer registro - lo que quiere decir que cada artista se cuenta una única vez.
Hemos descubierto que el número de artistas llega a lo indicado por Spotify el día 2024-11-24 (24 de noviembre). Gracias a esto, se puede proceder con la certeza de que tenemos los datos en el mismo marco temporal que Spotify. Sin embargo, no vamos a aplicar la funcion filter a my_spotify todavía, vamos a ver si esta fecha coincide con la que obtenemos del total de canciones diferentes y el total de minutos escuchados.
Canciones este año
Según Spotify, he escuchado un total de 2745 canciones diferentes este año. Vamos a hacer lo mismo que en el apartado de los artistas:
Según nuestro dataset, hemos escuchado 4196 canciones diferentes.
Aqui si que hay una diferencia considerable entre el dato que obtenemos de nuestro dataset y el que obtenemos de Spotify. De todas formas vamos a proceder a calcular la fecha de referencia
El dia en el que el total de canciones diferentes llega al numero indicado por Spotify es el 2024-07-24 (24 de julio), nada que ver con la fecha extraida del total de artistas diferentes. Resulta un tanto confuso ya que esperaba que las fechas coincidieran o se acercaran un poco más, y 4 meses de diferencia es demasiada.
Mis minutos de escucha
Vamos a hacer lo mismo que en los 2 anteriores apartados, esta vez para los minutos totales de escucha, que, según Spotify, son 20911
Según nuestro dataset hemos escuchado un total de 22402 minutos de música, siendo el día que más minutos he escuchado el 2024-07-28 con un total de 552 minutos escuchados (otro dato que Spotify lleva mal)
En este caso, el dia en el que los datos coinciden (2024-11-16) es un poco más cercano a la primera fecha obtenida, pero sigue sin coincidir.
Resulta extremadamente complejo obtener una conclusión lógica sobre el funcionamiento de los intervalos temporales seleccionados por Spotify para crear el Wrapped, ya que parece que cada dato individual ha sido obtenido en una fecha diferente y seleccionado de manera aparentemente arbitraria.
Otra explicación podría ser que el intervalo temporal es anterior al 1 de enero de 2024, pero por motivos evidentes (un Wrapped de 2024 no deberia tener datos de 2023) no voy a proceder a cambiar ese criterio en mi base de datos.
Mis artistas favoritos
Según datos de Spotify, mi artista más escuchado es mimofr, con un total de 497 minutos de escucha. Me sorprende mucho, porque este artista hace unas canciones (instrumentales) muy cortas que no he escuchado durante más tiempo que el resto de los artistas. Me sorprende aún más cuando, en la lista del top 5 de artistas, no aparezca mi músico favorito de la actualidad, Masayoshi Takanaka (un genio, lo quiero mucho). Os dejo abajo una cancion de prueba, por si a alguien le interesa:
Para averiguar cómo recolecta los datos Spotify para realizar el Wrapped, voy a extraer el top de artistas en 2 formatos diferentes: El tiempo reproducido de cada artista y el número de reproducciones únicas.
EFECTIVAMENTE! El top 5 de artistas que tiene Spotify y el que he calculado yo no son iguales. Si nos basamos en el tiempo de escucha de cada artista, mimofr baja al tercer puesto, siendo superado en minutos por Daft Punk y el previamente mencionado Masayoshi Takanaka. Entonces, ¿de donde sale este top 5? ¿Cómo esta contabilizando Spotify a quién escucho más?
Ahora sí que coinciden los datos, lo que nos confirma que Spotify recolecta los tops de artistas basándose en el número de reproducciones y no en el tiempo de escucha.
Me parece una forma de medirlo muchísimo peor que si se midiera en minutos: en el caso de que escuchara artistas con canciones muy largas (DJ’s o artistas de electrónica, rock, metal, etc.) y artistas con canciones muy cortas (instrumentales, música liminal, etc.), ¿no sería coherente medirlo todo basándose en el tiempo que le dedico a escuchar la música, en vez de en cuántas veces le he dado al botón de play?
Mis canciones favoritas
Según datos de Spotify, mi canción más escuchada es Never Let Go Of Me, con un total de 113 reproducciones. De nuevo, es probable que la canción que haya escuchado más tiempo sea una diferente, ya que estoy casi seguro de que Spotify se ha basado en el número de reproducciones en este caso también.
Para averiguarlo voy a extraer el top de canciones en 2 formatos diferentes: El tiempo reproducido de cada artista y el número de reproducciones únicas. Esta vez, lo enseñaré en un formato de gráfico (por no repetir el formato de las tablas anteriores)
horasmusica <- my_spotify %>%group_by(dia) %>%group_by(dia =floor_date(dia, "week")) %>%summarize(horas =sum(minutos) /60) %>%arrange(dia) %>%ggplot(aes(x = dia, y = horas)) +geom_col(aes(fill = horas)) +scale_fill_gradient(low ="#1db954", high ="#1db954") +labs(x="FECHA", y="HORAS",title ="Gráfico 1: Horas de música escuchadas en 2024",subtitle ="(Diferenciando entre semanas)",caption ="Fuente: Datos de mi propia cuenta de Spotify") +theme(legend.position ="none")horasmusica
Fin del proyecto
Con esto concluye mi entrega! Espero que te haya gustado!
Debajo hay un trozo de código adicional para más detalles de la sesión.
---title: "Spotify Wrapped 2024 en R"description: | Comparando los datos del Wrapped oficial con los propiosauthor:- name: Carlos Eduardo Albornoz Manzano (almancar@alumni.uv.es) affiliation: Universitat de València, Facultat d'Economia affiliation-url: https://www.uv.esdate: 2024-12-30categories: [trabajo BigData, Spotify, Spotify Wrapped] title-block-banner: "#1db954"title-block-style: defaulttitle-block-banner-color: blackformat: html: page-layout: full fontcolor: black linkcolor: green backgroundcolor: "#dcdcdc" smooth-scroll: truecss: ./assets/my_styles.css ---# Introducción::: column-margin{fig-align="center"}:::Vamos a utilizar los datos de nuestro histórico de la cuenta de Spotify. Se tienen que solicitar a través de la sección de privacidad de nuestra cuenta ([a través de este enlace se puede](https://www.spotify.com/es/account/privacy/)).La intención es emular el Spotify Wrapped original, además de poder constatar si los datos mostrados por el Wrapped coinciden con los obtenidos por nuestra cuenta.Si se manipulan los datos del archivo .json para meterlo todo en un archivo, este código puede servirle a cualquier persona que quiera hacer lo mismo!------------------------------------------------------------------------# Creando el dataframe para el análisisUna vez solicitado el historial de reproducción ampliado, tras pasar unos días recibiremos en nuestro correo una carpeta con varios archivos, con formato .json.Para poder cargar de manera más sencilla los datos dentro de RStudio, he seleccionado previamente los archivos con información de 2024 y los he fusionado (en el bloc de notas, con un simple copia-pega) para tener sólo 1 archivo .json.**Importante:** Respetar el formato de los archivos .json es necesario para que la carga de los datos no contenga errores, sobretodo hay que ir con cuidado de no equivocarse con un símbolo tipo "{"; "}"; "["; "]" o similares.Un problema adicional que tiene el archivo del histórico es que viene en formato nested, es decir, que cada reproducción está representada por un bloque de texto, no una fila o una columna, por lo que no puede ser interpretado directamente como un dataframe por el programa. Por eso, utilizaremos el paquete jsonlite para extraer los datos de nuestro archivo .json y convertirlo en un dataframe sobre el cual poder trabajar. En esta parte del código también añadimos los paquetes con los que vayamos a trabajar a lo largo del código.```{r}library(jsonlite) #install.packages(jsonlite)library(tidyverse) #install.packages(tidyverse)library(plotly) #install.packages(plotly)library(ggthemes) #install.packages(ggthemes)library(gt) #install.packages(gt)library("vembedr") #install.packages("vembedr")historial.completo <-fromJSON("assets/data.json", flatten =TRUE)```El dataset contiene observaciones sobre un conjunto de `r nrow(historial.completo)` reproducciones de canciones. Hay `r ncol(historial.completo)` variables, pero no todas son necesarias o útiles para el análisis que queremos realizar, por lo que podemos eliminar algunas y editar otras.Llama especialmente la atención que el dataframe tiene las fechas/timestamps en formato character, no en formato date. Para ello, utilizaremos el paquete lubridate para crear una nueva variable en formato date que nos será útil más adelante. Adicionalmente, nos desharemos de las variables que no nos interesan para el análisis:```{r}my_spotify <- historial.completo %>%mutate(fechahora =as_datetime(ts, tz =NULL, format =NULL))my_spotify <- my_spotify [, -c(1,2,4,5,9,10,11,12)]my_spotify <- my_spotify [, -c(13,14,15,16,17,18,19)]```Para terminar de "limpiar" el dataframe:- Renombramos aquellas variables con nombres extensos para facilitar la redacción del código- Añadimos nuevas variables para identificar el tiempo de reproducción en minutos y segundos- Sustituimos la franja horaria por default (UTC) por la nuestra (GMT+1)- Filtramos los datos anteriores al 1 de enero de 2024```{r}my_spotify <- my_spotify %>%rename(cancion = master_metadata_track_name) %>%rename(album = master_metadata_album_album_name) %>%rename(artista = master_metadata_album_artist_name)my_spotify <- my_spotify %>%mutate(dia =as_date(fechahora, tz ="UTC")) %>%mutate(fechahora = fechahora +hours(1) ) %>%mutate(segundos = ms_played /1000) %>%mutate(minutos = segundos /60)my_spotify <- my_spotify %>%filter(dia >="2024-01-01")```------------------------------------------------------------------------# Comparando los datos de Spotify Wrapped## Artistas este año::: column-margin{fig-align="center"}:::Según Spotify, he escuchado a 2070 artistas diferentes a lo largo del año. Intentaremos replicar este dato utilizando el siguiente código:```{r}artistasunicos <- my_spotify %>%summarize(totalartistas =n_distinct(artista))```El código indica que hemos escuchado un total de `r artistasunicos` artistas diferentes. No es el mismo dato, pero se acerca lo suficiente como para considerar que no se trata de un error en el cálculo de Spotify, si no que existe una diferencia en el marco temporal elegido, ya que yo he recibido datos posteriores a la fecha de la publicación del Wrapped.### "Reverse Engineering" el intervalo temporalCon el siguiente trozo de código representaré la evolución del número de artistas diferentes escuchados a lo largo del año, intentando encontrar el día exacto en el que ese número llega a los 2070 que indica Spotify, para así estar seguro de que los datos empleados son los mismos que los de Spotify.Este fragmento de código ha sido especialmente complejo hasta encontrar el uso correcto para *distinct* del paquete *dplyr*, que elimina los duplicados globales del dataset. Por ejemplo, independientemente del numero de veces que haya escuchado, por ejemplo, a Daft Punk, *distinct* no tiene en cuenta ninguno excepto el primer registro - lo que quiere decir que cada artista se cuenta una única vez.```{r}artistasunicos_acumulado <- my_spotify %>%arrange(dia) %>%distinct(artista, .keep_all =TRUE) %>%group_by(dia) %>%summarize(totalartistas =n_distinct(artista)) %>%mutate(sumaartistas =cumsum(totalartistas))graficoartistas <- artistasunicos_acumulado %>%ggplot(aes(x = dia, y = sumaartistas)) +geom_col(aes(fill = sumaartistas)) +scale_fill_gradient(high ="#1db954", low ="#1db954") +labs(x ="Fecha", y ="Nº artistas") +ggtitle("Número acumulado de artistas únicos escuchados") +theme_minimal()+scale_x_date(date_labels ="%b %Y", date_breaks ="1 month")+theme(axis.text.x =element_text(angle =45, hjust =1))+theme(legend.position ="none")diadatos <- artistasunicos_acumulado %>%filter(sumaartistas >=2070)%>%slice_head(n =1) %>%pull(dia)graficoartistas```Hemos descubierto que el número de artistas llega a lo indicado por Spotify el día `r diadatos` (24 de noviembre). Gracias a esto, se puede proceder con la certeza de que tenemos los datos en el mismo marco temporal que Spotify. Sin embargo, no vamos a aplicar la funcion *filter* a my_spotify todavía, vamos a ver si esta fecha coincide con la que obtenemos del total de canciones diferentes y el total de minutos escuchados.## Canciones este añoSegún Spotify, he escuchado un total de 2745 canciones diferentes este año. Vamos a hacer lo mismo que en el apartado de los artistas:```{r}cancionesunicas <- my_spotify %>%summarize(totalcanciones =n_distinct(cancion))```Según nuestro dataset, hemos escuchado `r cancionesunicas` canciones diferentes.::: column-margin{fig-align="center"}:::Aqui si que hay una diferencia considerable entre el dato que obtenemos de nuestro dataset y el que obtenemos de Spotify. De todas formas vamos a proceder a calcular la fecha de referencia```{r}cancionesunicas_acumulado <- my_spotify %>%distinct(cancion, .keep_all =TRUE) %>%arrange(dia) %>%group_by(dia) %>%summarize(totalcanciones =n_distinct(cancion)) %>%mutate(sumacanciones =cumsum(totalcanciones))graficocanciones <- cancionesunicas_acumulado %>%ggplot(aes(x = dia, y = sumacanciones)) +geom_col(aes(fill = sumacanciones)) +scale_fill_gradient(high ="#1db954", low ="#1db954") +labs(x ="Fecha", y ="Nº canciones") +ggtitle("Número acumulado de canciones únicas escuchadas") +theme_minimal()+scale_x_date(date_labels ="%b %Y", date_breaks ="1 month")+theme(axis.text.x =element_text(angle =45, hjust =1))+theme(legend.position ="none")diadatos2 <- cancionesunicas_acumulado %>%filter(sumacanciones >=2745)%>%slice_head(n =1) %>%pull(dia)graficocanciones```El dia en el que el total de canciones diferentes llega al numero indicado por Spotify es el `r diadatos2` (24 de julio), nada que ver con la fecha extraida del total de artistas diferentes. Resulta un tanto confuso ya que esperaba que las fechas coincidieran o se acercaran un poco más, y 4 meses de diferencia es demasiada.## Mis minutos de escuchaVamos a hacer lo mismo que en los 2 anteriores apartados, esta vez para los minutos totales de escucha, que, según Spotify, son 20911::: column-margin{fig-align="center"}:::```{r}minutosescucha <- my_spotify %>%summarize(totalminutos =sum(minutos))%>%pull(totalminutos) %>%as.integer()topmin <- my_spotify %>%group_by(dia) %>%summarize(totalminutos =sum(minutos)) %>%arrange(desc(totalminutos)) %>%slice_head(n =1)topmin_dia <- topmin%>%pull(dia)topmin_min <- topmin%>%pull(totalminutos) %>%as.integer()```Según nuestro dataset hemos escuchado un total de `r minutosescucha` minutos de música, siendo el día que más minutos he escuchado el `r topmin_dia` con un total de `r topmin_min` minutos escuchados (otro dato que Spotify lleva mal)```{r}totalminutos <- my_spotify %>%arrange(dia) %>%group_by(dia) %>%summarize(totalminutos =sum(minutos))%>%mutate(sumaminutos =cumsum(totalminutos))graficominutos <- totalminutos %>%ggplot(aes(x = dia, y = sumaminutos)) +geom_col(aes(fill = sumaminutos)) +scale_fill_gradient(high ="#1db954", low ="#1db954") +labs(x ="Fecha", y ="Nº minutos") +ggtitle("Número total de minutos escuchados") +theme_minimal()+scale_x_date(date_labels ="%b %Y", date_breaks ="1 month")+theme(axis.text.x =element_text(angle =45, hjust =1))+theme(legend.position ="none")diadatos3 <- totalminutos %>%filter(sumaminutos >=20911)%>%slice_head(n =1) %>%pull(dia)graficominutos```En este caso, el dia en el que los datos coinciden (`r diadatos3`) es un poco más cercano a la primera fecha obtenida, pero sigue sin coincidir. ***Resulta extremadamente complejo obtener una conclusión lógica sobre el funcionamiento de los intervalos temporales seleccionados por Spotify para crear el Wrapped, ya que parece que cada dato individual ha sido obtenido en una fecha diferente y seleccionado de manera aparentemente arbitraria.*** Otra explicación podría ser que el intervalo temporal es anterior al 1 de enero de 2024, pero por motivos evidentes (un Wrapped de 2024 no deberia tener datos de 2023) no voy a proceder a cambiar ese criterio en mi base de datos.## Mis artistas favoritos::: column-margin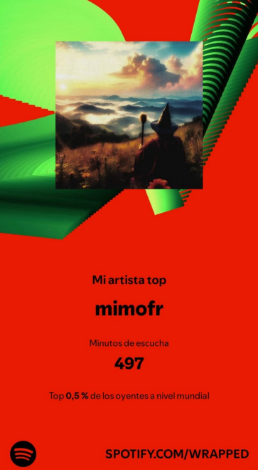{fig-align="center"}:::Según datos de Spotify, mi artista más escuchado es **mimofr**, con un total de 497 minutos de escucha. Me sorprende mucho, porque este artista hace unas canciones (instrumentales) muy cortas que no he escuchado durante más tiempo que el resto de los artistas. Me sorprende aún más cuando, en la lista del top 5 de artistas, no aparezca mi músico favorito de la actualidad, Masayoshi Takanaka (un genio, lo quiero mucho). Os dejo abajo una cancion de prueba, por si a alguien le interesa: {{< video https://www.youtube.com/watch?v=Bt-GKv1qfXg&list=PLS4TSWjaLO8mTrAyWkW-WRjPyNjjFNo8m >}}Para averiguar cómo recolecta los datos Spotify para realizar el Wrapped, voy a extraer el top de artistas en 2 formatos diferentes: El tiempo reproducido de cada artista y el número de reproducciones únicas.### Top 5 (tiempo)```{r}top5artistas_tiempo <- my_spotify %>%group_by(artista) %>%summarize(minutosartista =sum(minutos)) %>%arrange(desc(minutosartista)) %>%slice_head(n =5)topartista_tiempo <- top5artistas_tiempo%>%slice_head(n=1)%>%pull(minutosartista)%>%as.integer()topartista <- top5artistas_tiempo%>%slice_head(n=1)%>%pull(artista)top5artistas_tiempo %>%gt() %>%tab_header (title ="Top 5 artistas 2024 - Playtime",subtitle ="Minutos escuchados por artista" ) %>%cols_label(artista ="Artista",minutosartista ="Minutos" ) %>%fmt_number (columns ="minutosartista",decimals =0 )```::: column-margin{fig-align="center"}:::EFECTIVAMENTE! El top 5 de artistas que tiene Spotify y el que he calculado yo no son iguales. Si nos basamos en el tiempo de escucha de cada artista, **mimofr** baja al tercer puesto, siendo superado en minutos por **Daft Punk** y el previamente mencionado **Masayoshi Takanaka**. Entonces, ¿de donde sale este top 5? ¿Cómo esta contabilizando Spotify a quién escucho más?### Top 5 (nº reproducciones)```{r}top5artistas_reproducciones <- my_spotify %>%group_by(artista) %>%summarize(reproducciones =n()) %>%arrange(desc(reproducciones)) %>%slice_head(n =5)top5artistas_reproducciones_tabla <- top5artistas_reproducciones %>%gt() %>%tab_header(title ="Top 5 artistas 2024 - Reproducciones",subtitle ="Número de reproducciones por artista" ) %>%cols_label(artista ="Artista",reproducciones ="Reproducciones" ) %>%fmt_number(columns ="reproducciones",decimals =0 )top5artistas_reproducciones_tabla```Ahora sí que coinciden los datos, lo que nos confirma que **Spotify recolecta los tops de artistas basándose en el número de reproducciones y no en el tiempo de escucha**.Me parece una forma de medirlo muchísimo peor que si se midiera en minutos: en el caso de que escuchara artistas con canciones muy largas (DJ's o artistas de electrónica, rock, metal, etc.) y artistas con canciones muy cortas (instrumentales, música liminal, etc.), ¿no sería coherente medirlo todo basándose en el tiempo que le dedico a escuchar la música, en vez de en cuántas veces le he dado al botón de play?## Mis canciones favoritas::: column-margin{fig-align="center"}:::Según datos de Spotify, mi canción más escuchada es **Never Let Go Of Me**, con un total de 113 reproducciones. De nuevo, es probable que la canción que haya escuchado más tiempo sea una diferente, ya que estoy casi seguro de que Spotify se ha basado en el número de reproducciones en este caso también.Para averiguarlo voy a extraer el top de canciones en 2 formatos diferentes: El tiempo reproducido de cada artista y el número de reproducciones únicas. Esta vez, lo enseñaré en un formato de gráfico (por no repetir el formato de las tablas anteriores)### Top 5 (tiempo)```{r}topcanciones_tiempo <- my_spotify %>%group_by(cancion) %>%summarize(totalminutos =sum(minutos)) %>%arrange(desc(totalminutos)) %>%slice_head(n =5)topcancion_tiempo <- topcanciones_tiempo%>%slice_head(n=1)%>%pull(totalminutos)%>%as.integer()topcancion <- topcanciones_tiempo%>%slice_head(n=1)%>%pull(cancion)t5tiempografico <- topcanciones_tiempo %>%ggplot(aes(x =reorder(cancion, totalminutos), y = totalminutos)) +geom_col(aes(fill = totalminutos)) +scale_fill_gradient(low ="#1db954", high ="#1db954") +labs(x="", y="Minutos") +ggtitle("Top 5 canciones más escuchadas") +theme(axis.text.x =element_text(angle =90)) +theme(legend.position ="none")+coord_flip()t5tiempografico```::: column-margin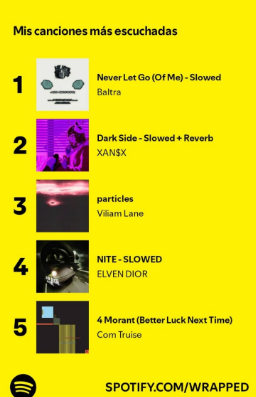{fig-align="center"}:::### Top 5 (nº reproducciones)```{r}topcanciones_repro <- my_spotify %>%group_by(cancion) %>%summarize(reproducciones =n()) %>%arrange(desc(reproducciones)) %>%slice_head(n =5) t5reprografico <- topcanciones_repro%>%ggplot(aes(x =reorder(cancion, reproducciones), y = reproducciones)) +geom_col(aes(fill = reproducciones)) +scale_fill_gradient(low ="#1db954", high ="#1db954") +labs(x="", y="Reproducciones") +ggtitle("Top 5 canciones más reproducidas") +theme(axis.text.x =element_text(angle =90)) +theme(legend.position ="none")+coord_flip()t5reprografico ```Nuevamente, la lista vuelve a estar basada en la cantidad de veces que le das al play a una canción y no en los minutos que pasas escuchándola# El Wrapped definitivo con nuestros propios datos: - **He escuchado a `r artistasunicos` artistas** - **He escuchado `r cancionesunicas` canciones este año** - **He escuchado `r minutosescucha` minutos de música. El día que más escuche fue el `r topmin_dia`, con `r topmin_min` minutos.** - **Mi artista más escuchado es `r topartista`, con un total de `r topartista_tiempo` minutos escuchados.** - **Mi canción más escuchada es `r topcancion`, con un total de `r topcancion_tiempo` minutos escuchados.**```{r}top5canciones_tiempo_tabla <- topcanciones_tiempo %>%gt() %>%tab_header (title ="Top 5 canciones",subtitle ="Minutos escuchados por canción" ) %>%cols_label(cancion ="Cancion",totalminutos ="Minutos" ) %>%fmt_number (columns =everything(),decimals =0 )top5canciones_tiempo_tabla``````{r}top5artistas_reproducciones_tabla```## Otras funciones interesantes### Nº de artistas escuchados cada día```{r}artistaspordia <- my_spotify %>%group_by(dia) %>%summarize(totalartistas =n_distinct(artista)) %>%arrange(dia) %>%ggplot(aes(x = dia, y = totalartistas)) +geom_col(aes(fill = totalartistas)) +scale_fill_gradient(high ="#1db954", low ="#1db954") +labs(x="Fecha", y="Nº artistas") +ggtitle("Numero de artistas escuchados") +theme(legend.position ="none")artistaspordia```### Total de horas escuchadas cada semana```{r}horasmusica <- my_spotify %>%group_by(dia) %>%group_by(dia =floor_date(dia, "week")) %>%summarize(horas =sum(minutos) /60) %>%arrange(dia) %>%ggplot(aes(x = dia, y = horas)) +geom_col(aes(fill = horas)) +scale_fill_gradient(low ="#1db954", high ="#1db954") +labs(x="FECHA", y="HORAS",title ="Gráfico 1: Horas de música escuchadas en 2024",subtitle ="(Diferenciando entre semanas)",caption ="Fuente: Datos de mi propia cuenta de Spotify") +theme(legend.position ="none")horasmusica```# Fin del proyectoCon esto concluye mi entrega! Espero que te haya gustado!*Debajo hay un trozo de código adicional para más detalles de la sesión.*------------------------------------------------------------------------```{r}#| echo: falsesessioninfo::session_info() %>% details::details(summary ='current session info') ```














